Last edited time
Aug 7, 2024 10:22 AM
type
Post
status
Published
date
Mar 13, 2024
summary
该文档介绍了如何使用
whisper.cpp进行语音转文字,包括克隆项目、获取和编译模型、运行示例、微调模型、内存占用、模型量化、Core ML支持、N卡加速及实时音频转文字功能。提供了详细的命令行示例和注意事项,适合对人工智能和语音处理感兴趣的用户。tags
推荐
人工智能
实用教程
password
URL
category
技术分享
只有whisper.cpp文件和whisper.h文件是项目的核心文件,其他代码都是ggml的机器学习框架代码。
examples中的代码是命令行中调用
./main ***时实际调用whisper.cpp文件进行语音转文字的代码,可以自定义修改,令输出不再固定于范例格式。快速开始
克隆 whisper.cpp
获取模型
为了能够在C/C++中加载,OpenAI提供的原始Whisper PyTorch模型(opens in a new tab)被转换成自定义的ggml格式。转换是通过
convert-pt-to-ggml.py(opens in a new tab) 脚本执行的。有三种方法可以获取模型
- 使用
download-ggml-model.sh(opens in a new tab) 下载预转换的模型
例子
- 手动下载预转换的模型
ggml 模型可以从以下位置获取:
示例转换,假设原始的 PyTorch 文件已下载到
~/.cache/whisper。将 ~/path/to/repo/whisper/ 更改为您 Whisper 源代码副本的位置:编译
现在,我们构建主示例。
运行
注意,当前whisper.cpp的main示例仅支持16bit的wav媒体文件!所以在执行前需要先把媒体文件转为这个格式。
可以通过如下命令解决:
微调模型
社区正在努力创建使用额外训练数据进行细调的 Whisper 模型。例如,这篇博文描述了使用 Hugging Face (HF) Transformer 实现的 Whisper 进行微调的方法。
生成的模型与原始的 OpenAI 格式略有不同。要读取 HF 模型,您可以使用
convert-h5-to-ggml.py脚本,如下所示:内存占用
Model | Disk | Mem |
tiny | 75 MiB | ~273 MB |
base | 142 MiB | ~388 MB |
small | 466 MiB | ~852 MB |
medium 1.5 GiB | ~2.1 GB | ㅤ |
large | 2.9 GiB | ~3.9 GB |
模型量化
whisper.cpp 支持对 ggml 模型进行量化,从而减少内存占用。要量化模型,请使用以下命令:Core ML 支持
在苹果系列芯片的设备上,编码器推断可以通过 Core ML 在苹果神经引擎(ANE)上执行。这可以导致显著的加速,与仅 CPU 执行相比,速度提高了 3 倍以上。以下是生成 Core ML 模型并将其与 whisper.cpp 一起使用的说明:
安装所需要的库
想要成功安装
coremltools,你必须要安装 XCode 并且执行 xcode-select --install 安装命令行工具(一般安装git时这个也会一起安装)。 - 建议使用conda创建python虚拟环境,并且使用python 3.10版本 - 建议使用macos14即以上版本。生成 Core ML 模型
举例如果是生成基于 base.en 模型的 Core ML 模型,执行以下命令:
打包编译
运行
N卡支持
在支持n卡的机器上,可以开启N卡加速。
请确保你安装了cuda
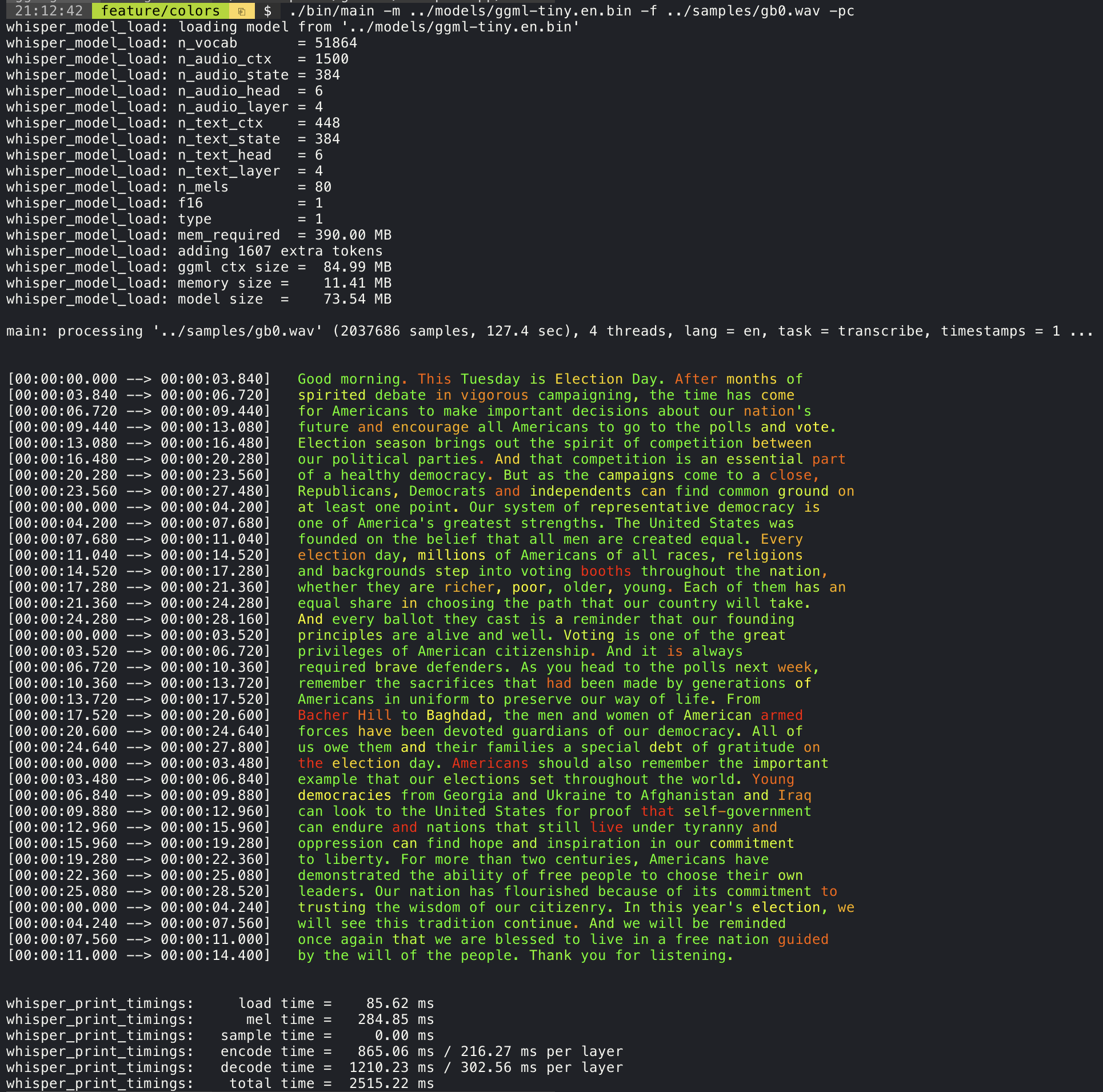
实时音频转文字
信心程度显示
这种方式下会通过使用不同的颜色显示文字来表示 whisper.cpp 对音频的识别信心程度。